数据字典应该是数据管理领域非常核心的东西,如果说,语言是人类世界沟通的方法,数据字典则是数据世界沟通的语言,任何数据都需要通过看得懂的方式表达出来,只有懂这个数据什么意思,才有基于数据创造的可能,才能实现数据知识的传承。
但很多企业并没做数据字典,或不重视,为什么?
一是非眼前事,以后做也成,不做暂时也没影响;
二是难度比较高,产出却遥遥无期;
三是不够显性化,做数据字典很难引起领导重视,BI创造亮点和业务价值才是正事。
而只有当企业的数据字典成为公司数据采集、开发、分析及应用的必备工具后,才能感觉到这项工作地完成其实迟到了很多年。
如何启动数据字典梳理这项工作?
企业数据字典的梳理是个浩大的工程,但看似不可能完成的任务,如果真的花功夫去研究,其实还是有可能做到的。
先完成基于表级的梳理,搞清楚每张表的业务含义和获取方式,这有助于第一个阶段性成果的达成,也正是有了表级的指导,后续才可以将字段级的梳理要求清晰的分配下去。
一个企业,其业务和数据的沉淀到了一定水平,人员充足,是有能力完成这项工作的,但开头的确非常不易,毕竟梳理数据字典,也是讲究一定方法和套路的。
有必要启动数据字典梳理工作的另一个原因是:公司如果要建设大数据平台,却没有完整的数据字典,那这项工程能否如期保质完成就成了未知数。不能总指望用原先的BI的数据接口来应付,而应该利用一切机会把公司的资产梳理清楚。
采用什么样的方法和步骤?
一是确定规划目录:
原则上应该自顶向下梳理,先通过调研确定总体结构分类,然后分主题进行,由于本次梳理的范围较大,暂时以源系统方式梳理开始,不强调目录分类的科学性,仅强调梳理的便捷性,以下是B域的目录示例。
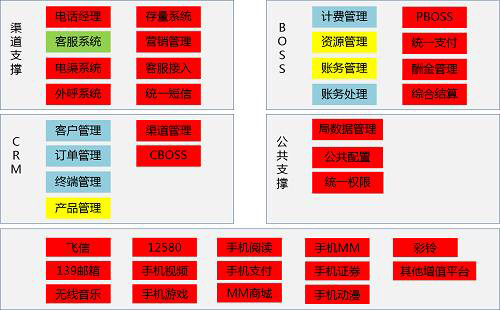
二是确定参考材料:
从源系统负责人搜刮到的BOSS/CRM等系统所有现存的PDM,SVN上存在的所有概要设计文档为依据,梳理的参考材料会按照系统分门别类保存,作为输出物,方便后来人参考,算是梳理的副产品,的确没有一个地方有完整的源系统资料。
三是确定干系人:
很多知识都留在开发人员脑子里,现有的资料不足以解释当前的实际业务和数据,因此确定了干系人名单,这个工作也很重要,以下示例了各个系统对应的合作伙伴和联系人。
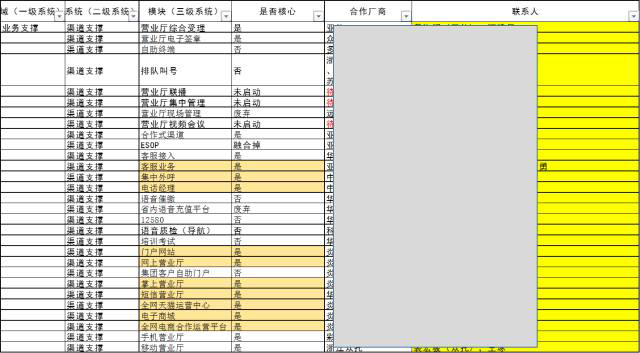
做数据的,有必要跟源系统的开发等人员混熟,否则涉及一些深层次的问题,没人能够解答,必须要开发人员出马。
四是理解逻辑视图:
系统的逻辑模型对于理解数据的业务意义和价值至关重要,因此首先需要从PDM或概要设计找到模型去理解业务,这个是最艰难的,梳理数据字典不是拿着PDM来直接抄就可以了,要把业务理解清楚,才能写出很好的说明,反映出各种实体的关系。以下列出了产品系统中涉及的相关表,务必要搞清楚各个子主题及各表之间的关系,表的关系图在PDM,因此不罗列。
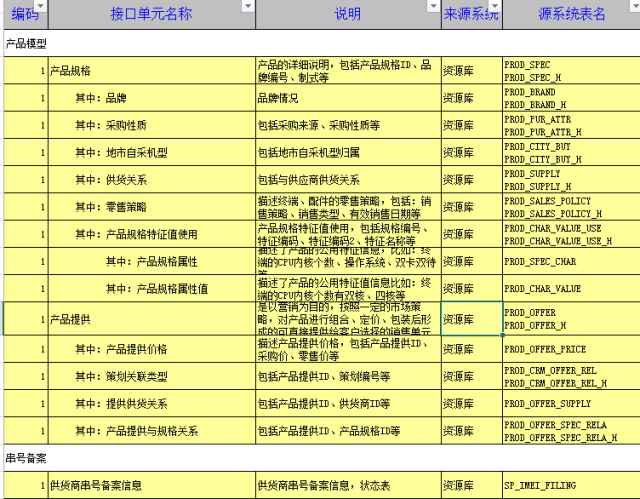
五是理解数据实体:
首先,针对每个表或数据实体查看实体的注释,大致理解用途,然后再看字段,然后再看建表语句,会有很多有用的枚举注释。
其次,在数据库中找到这张表,查看真实数据,加深对于数据的理解,比如假如表为空,一般表不会太重要,如果某字段值基本为空,则字段不会太重要,很多文档中的表早已经失效,需要亲力亲为去核验。
最后,理解数据的关键是实体间的关系,比如看到用户表,自然想到用户肯定能关联到客户,那如何关联起来呢,因此需要自己找实例去验证想法;比如看到策划订单,自然想到客户订单跟它是什么关系。
梳理的过程也是对以往零碎的知识的查漏补缺过程,非常有价值,对于源系统会有更深的理解。
那么,梳理的要素有哪些呢?
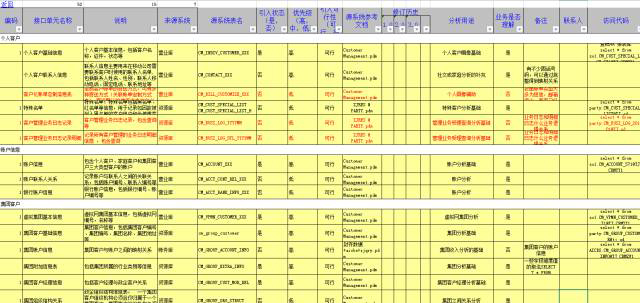
以下列出了每个实体的13个梳理要素,方便参考,但不同企业情况不同,可以根据实际情况做增减。
1、实体名称:一般是表的中文表名,由于数据可能有层级关系,在一些主题梳理时候,会体现一定的分层表达。
2、实体说明:对于表的业务理解往往体现在这里,一部分来源于源系统文档表的备注说明,另一部分来源于自己的理解,理解的越深入,这个说明就越有力量。
3、来源系统:来源于哪个系统,由于系统越来越多,访问方式越来越多,因此对于系统的命名和访问方式做了归纳。
4、源系统表名:来源于哪个源系统哪张具体表,如果涉及分地市,月份,年份等,会以通配符方式表达,一般XXX代表地市、YYYYMM代表年月、YYYY代表年、F代表报结、H代表历史等。
5、引入状态(是,否):与当前存量仓库模型的比对结果,如果仓库中有,就标识是,否则就标识否。
6、优先级:站在业务的角度看源系统数据的价值,高代表分析价值较大,应该优先引入,而一些前台配置表优先级就较低,当然这个判断带较多的个人色彩。
7、引入可行性:从技术角度和管理角度看数据引入的可行性,主要依赖主观判断。
8、业务用途:粗略判定数据可以用在哪个分析方面,主要依赖主观判断。
9、业务是否理解:对于源系统的业务和数据理解程度不够或有异议,暂时得不到解答,但不能死在这里吧,会填否,因为有时间要求。
10、联系人:对应的源系统的负责人,所谓冤有头债有主。
11、是访问代码:访问数据的原始SQL代码,方便验证数据,源系统库太多了,有时回过头来,忘记了哪是哪,因此务必梳理的时候记下来。
12、是采集周期:表明可以采集的最小周期。
13、是采集形式:表明是状态表还是流水表等,不同表影响具体的采集方式。
最后,梳理成什么样子呢?
首先是总体目录图,方便查看,如下图所示。
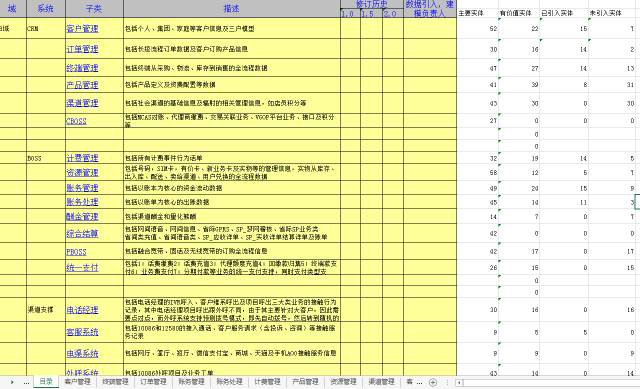
点击每个链接,就可以访问到对应的子系统,每个字系统的实体都作了说明,可以自己看有哪些要素:
PPT总结示例:
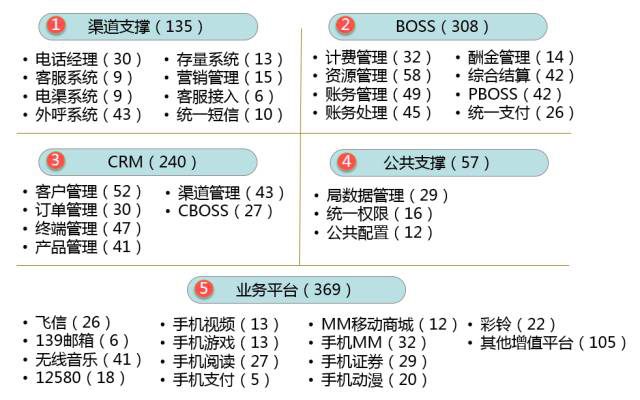
通过这一遍的梳理,公司的核心数据资产较以往仓库已引入的可获得成倍增长,且所有的表都重新进行了标注,为后续字段级的梳理打下了坚实的基础。