![]()
图 1-1大数据开发通用步骤图
上图只是一个简化后的步骤和流程,实际开发中,有的步骤可能不需要,有的还需要增加步骤,有的流程可能更复杂,因具体情况而定。
下面以Google搜索引擎为例,来说明以上步骤。
大数据采集
Google的数据来源于互联网上的网页,它们由Google Spider(蜘蛛、爬虫、机器人)来抓取,抓取的原理也很简单,就是模拟我们人的行为,来访问各个网页,然后保存网页内容。
Google Spider是一个程序,运行在全球各地的Google服务器之中,Spider们非常勤奋,日夜不停地工作。点击领取免费资料及课
2008年Google数据表明,它们每天都会访问大约200亿个网页,而在总量上,它们追踪着300亿个左右的独立URL链接。
可以说,只要是互联网上的网站,只要没有在robots.txt文件禁止Spider访问的话,其网页基本上都会在很短的时间内,被抓取到Google的服务器上。
全球的网页,这是典型的大数据。因此,Google Spider所做的就是典型的大数据采集工作。
大数据预处理
Google Spider爬取的网页,无论是从格式还是结构等,都不统一,为了便于后续处理,需要先做一些处理,例如,在存储之前,先转码,使用统一的格式对网页进行编码,这些工作就是预处理。
如果你想要学好大数据最好加入一个好的学习环境,可以来这个Q群529867072 这样大家学习的话就比较方便,还能够共同交流和分享资料
大数据存储
网页经过预处理后,就可以存储到Google的服务器上。
2008年,Google已经索引了全世界1万亿个网页,到2014年,这个数字变成了30万亿个。
为了减少开销,节约空间,Google将多个网页文件合并成一个大文件,文件大小通常在1GB以上。
这还是15年以前的数字,那时,主流台式机硬盘也就是60GB左右,1GB的文件在当时可以说是大文件了。
为了实现这些大文件高效、可靠、低成本存储,Google发明了一种构建在普通商业机器之上的分布式文件系统:Google File System,缩写为GFS,用来存储文件(又称之为非结构化数据)。
网页文件存储下来后,就可以对这些网页进行处理了,例如统计每个网页出现的单词以及次数,统计每个网页的外链等等。
这些被统计的信息,就成为了数据库表中的一个属性,每个网页最终就会成为数据库表中的一条或若干条记录。
由于Google存储的网页太多,30万亿个以上,因此,这个数据库表也是超级庞大的,传统的数据库,像Oracle等,根本无法处理这么大的数据,因此Google基于GFS,发明了一种存储海量结构化数据(数据库表)的分布式系统Bigtable。
上述两个系统(GFS和Bigtable)并未开源,Google仅通过文章的形式,描述了它们的设计思想。
所幸的是,基于Google的这些设计思想,时至今日,已经出现了不少开源海量数据分布式文件系统,如HDFS等,也出现了许多开源海量结构化数据的分布式存储系统,如Hbase、Cassandra等,它们分别用于不同类型大数据的存储。
总之,如果采集过来的大数据需要存储,要先判断数据类型,再确定存储方案选型;
如果不需要存储(如有的流数据不需要存储,直接处理),则直接跳过此步骤,进行处理。
大数据处理
网页存储后,就可以对存储的数据进行处理了,对于搜索引擎来说,主要有3步:
1)单词统计:统计网页中每个单词出现的次数;
2)倒排索引:统计每个单词所在的网页URL(Uniform Resource Locator统一资源定位符,俗称网页网址)以及次数;
3)计算网页级别:根据特定的排序算法,如PageRank,来计算每个网页的级别,越重要的网页,级别越高,以此决定网页在搜索返回结果中的排序位置。
例如,当用户在搜索框输入关键词“足球”后,搜索引擎会查找倒排索引表,得到“足球”这个关键词在哪些网页(URL)中出现,然后,根据这些网页的级别进行排序,将级别最高的网页排在最前面,返回给用户,这就是点击“搜索”后,看到的最终结果。
大数据处理时,往往需要从存储系统读取数据,处理完毕后,其结果也往往需要输出到存储。因此,大数据处理阶段和存储系统的交互非常频繁。
大数据可视化
大数据可视化是将数据以图形的方式展现出来,与纯粹的数字表示相比,图形方式更为直观,更容易发现数据之间的规律。
例如,Google Analytics是一个网站流量分析工具,它统计每个用户使用搜索引擎访问网站的数据,然后得到每个网站的流量信息,包括网站每天的访问次数,访问量最多的页面、用户的平均停留时间、回访率等,所有数据都以图形的方式,直观地显示出来,如图1-2所示
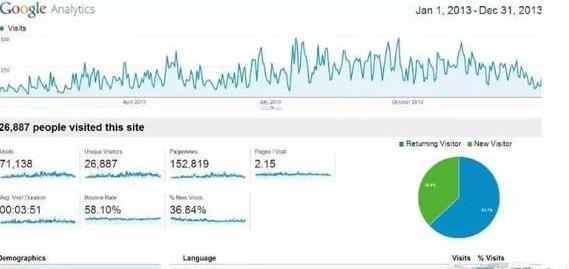
图1-2 Google网站访问量分析图